
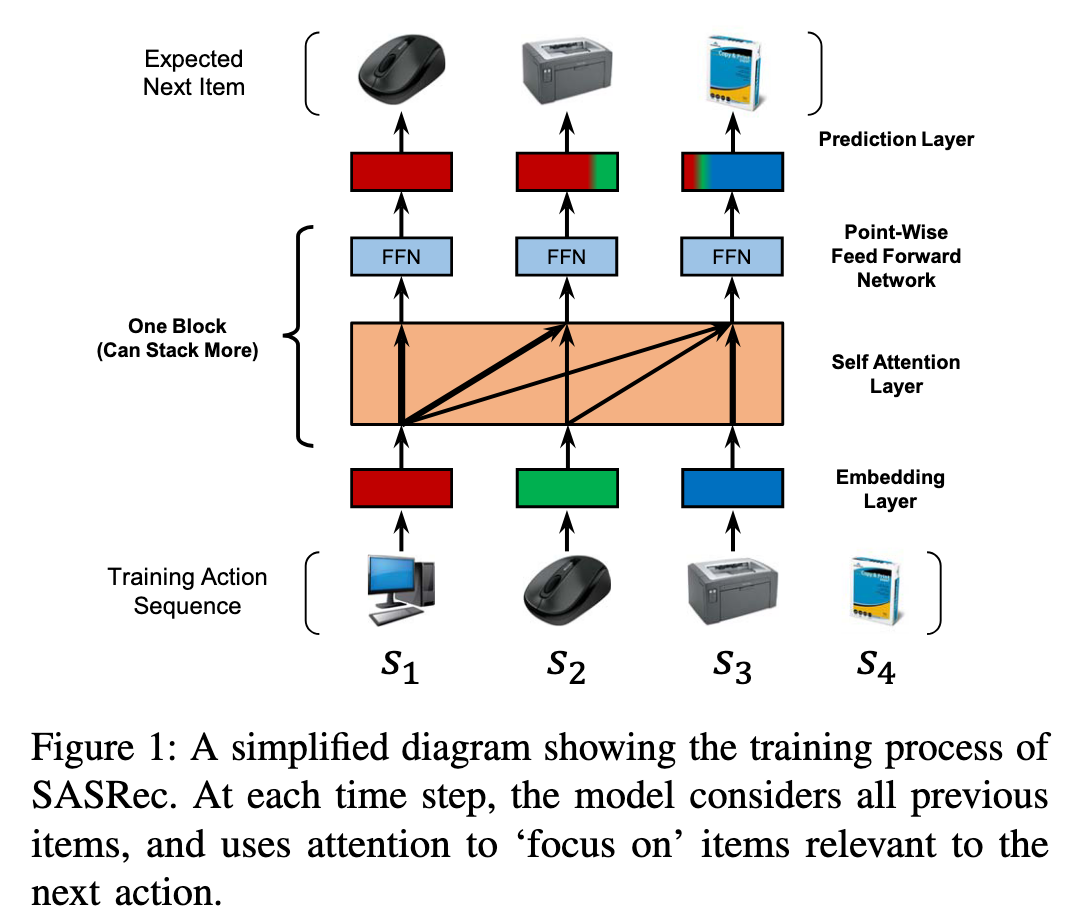
通过理解Fig.1可以理解本模型。注意:本文中的s1仅代表一个物品(可以理解为该序列/会话中的第一个物品,而不能理解为一个会话)。这样文中的E即表示一个序列构成的物品表达矩阵。
基于注意力机制(Q, K, V),可以对E进行改造,即所谓的投影:(EW^Q, EW^K, E^V),然后对投影后的表达执行注意力计算。这里有意思的是,作者阻断了后序物品对之前的物品的影响,即在聚合E^V时,是针对每一个物品进行的,而且只会聚合该物品与该物品之前的物品的表达(see, Last line of Causality in P3)。
所谓的FFN,就是将从上述得到的聚合后的每个物品的表达,输入到FFN当中做一个非线性化,如ReLU处理。好处之一:消除物品之间(点乘)的对称性。如果向量未经过非线形处理,则点乘是线性的,在提升V_i*V_j的同时,必定也提升了V_j*V_i。在序列关系中,V_i -> V_j 不代表V_j -> V_i,所以要消除对称性。消除对称性的方法除了加入非线形处理以外,还可以构造两个不同质的物品表达,如E_i * V_j和E_j * V_i (see, Shared Item Embedding in P4)。
本文讨论了显式用户建模和隐式用户建模(Explicit User Modeling in P4),前者有一个独立的用户表征(静态的);后者利用用户点击过的物品集合构建(聚合)出用户的表达(动态的)。
本文关于残差和Dropout处理值得借鉴(P4):在输入层执行正则化处理(例如减去均值再除以方差等),然后对神经元随机进行dropout处理,即算计放弃一些神经元。最后为了提升原始输入(变化前的物品表达)的重要性,在输出层加上原始表达。
以上几点提供了如何提升论文深度的角度,例如对某个设计的数学思考。
| 文献题目 | 去谷歌学术搜索 | ||||||||||
| Self-Attentive Sequential Recommendation | |||||||||||
| 文献作者 | Wang-Cheng Kang, Julian McAuley | ||||||||||
| 文献发表年限 | 2018 | ||||||||||
| 文献关键字 | |||||||||||
| ICDM;dropout;残差处理;点乘对称性;复杂度分析;内存分析(参数数量);神经网络技巧(残差输入) | |||||||||||
| 摘要描述 | |||||||||||
| Sequential dynamics are a key feature of many modern recommender systems, which seek to capture the ‘con- text’ of users’ activities on the basis of actions they have performed recently. To capture such patterns, two approaches have proliferated: Markov Chains (MCs) and Recurrent Neural Networks (RNNs). Markov Chains assume that a user’s next action can be predicted on the basis of just their last (or last few) actions, while RNNs in principle allow for longer-term semantics to be uncovered. Generally speaking, MC-based methods perform best in extremely sparse datasets, where model parsimony is critical, while RNNs perform better in denser datasets where higher model complexity is affordable. The goal of our work is to balance these two goals, by proposing a self-attention based sequential model (SASRec) that allows us to capture long-term semantics (like an RNN), but, using an attention mechanism, makes its predictions based on relatively few actions (like an MC). At each time step, SASRec seeks to identify which items are ‘relevant’ from a user’s action history, and use them to predict the next item. Extensive empirical studies show that our method outperforms various state-of-the-art sequential models (including MC/CNN/RNN-based approaches) on both sparse and dense datasets. Moreover, the model is an order of magnitude more efficient than comparable CNN/RNN-based models. Visual- izations on attention weights also show how our model adaptively handles datasets with various density, and uncovers meaningful patterns in activity sequences. | |||||||||||


