
这篇文章把代表用户的行向量或者代表物品的列向量当作一条信息表达,然后从信息的编码和解码的角度考虑了评分矩阵的复原.(区别于信息的分解?http://nuoku.vip/users/2/articles/85)
具体做法是结合NN算法:
![]()
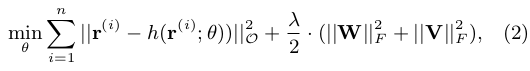
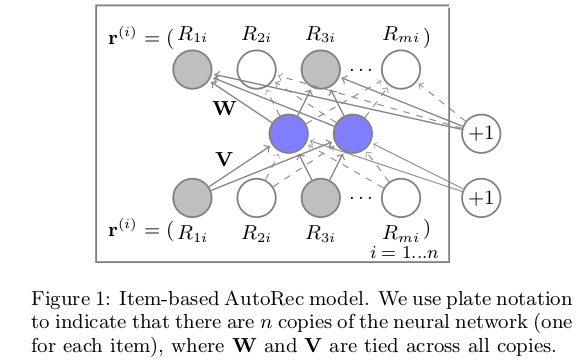
另行文表达方面,值得借鉴的地方: 本文在比较两个算法的几个角度值得参考和学习.
生成模型和判别模型的区别: http://www.cnblogs.com/jerrylead/archive/2011/03/05/1971903.html
最后,LibRec小编给各列出近几年将AutoEncoder用于推荐系统的相关论文:
Hybrid Recommender System based on Autoencoders, DLRS workshop, 2016
Collaborative Denoising Auto-Encoders for Top-N Recommender Systems, WSDM, 2016
Deep Collaborative Filtering via Marginalized Denoising Autoencoder, CIKM, 2015
Relational Stacked Denoising Autoencoder for Tag Recommendation, AAAI, 2015
Collaborative Filtering with Stacked Denoising AutoEncoders and Sparse Inputs, NIPS workshop, 2015
引用本文的一些文章值得阅读.
| 文献题目 | 去谷歌学术搜索 | ||||||||||
| AutoRec: Autoencoders Meet Collaborative Filtering | |||||||||||
| 文献作者 | Suvash Sedhain †∗ , Aditya Krishna Menon †∗ , Scott Sanner †∗ , Lexing Xie ∗ | ||||||||||
| 文献发表年限 | 2015 | ||||||||||
| 文献关键字 | |||||||||||
| Recommender Systems; Collaborative Filtering; Autoencoders; 编码,解码; 生成模型; 判别模型 | |||||||||||
| 摘要描述 | |||||||||||
| This paper proposes AutoRec, a novel autoencoder frame- work for collaborative filtering (CF). Empirically, AutoRec’s compact and efficiently trainable model outperforms state- of-the-art CF techniques (biased matrix factorization, RBM- CF and LLORMA) on the Movielens and Netflix datasets. | |||||||||||


