
LETOR (LEarning TO Rank)数据集下载地址: https://www.microsoft.com/en-us/research/project/letor-learning-rank-information-retrieval/?from=http%3A%2F%2Fresearch.microsoft.com%2Fen-us%2Fum%2Fbeijing%2Fprojects%2Fletor%2F%2Fletor3download.aspx
L2R 源于IR ( 用户输入query, 返回跟此query最为相关的documents, 并根据相关等进行排序).
本博文从以下几个方面阐述对L2R相关问题的理解:
L2R在IR中一般的Architecture
在介绍L2R在IR中的运用之前,先来简单了解下IR领域中一些启发式排序方法: 首先query和document一般都是以text形式存在的, 所以文本匹配是解决IR问题最为根本的技术. 基于文本匹配模式, 我们就能够提出很多用来计算query和document之间相关性的指标, 比如: TF-IDF, BM25, PageRank 等, 通过任意一个指标或这任意指标的加权就可以得到关于一个query的document list. 如果这个指标足够优秀,如PageRank, 我们可以之间根据这个相关性返回最终的推荐列表.
实际上,单单靠上述方法是存在一定的局限性的,因为单个指标考虑的面是有限的,即是各有侧重的. 那么组合这些指标进行排序就是一个很好的选择了,最直接的方法就是上面说的直接加权,形成更加综合的指标,另一种方法是借用机器学习方法,将这些指标作为特征一并进行学习.
L2R就是一种机器学习方法, 一般机器学习最基本的三要素: 特征, ground truth和optimization function. 在IR中,
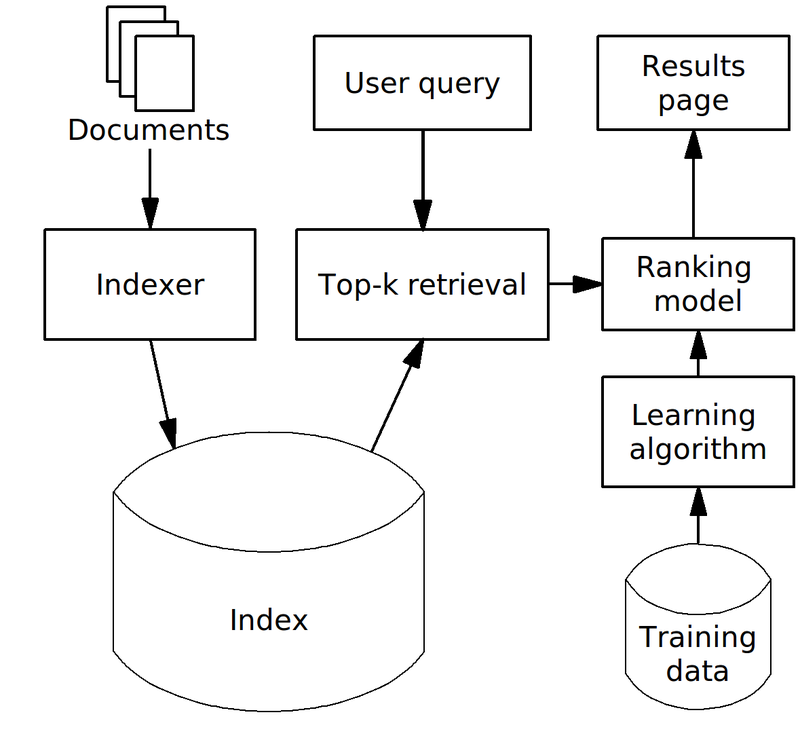
引用wiki图对L2R在IR中的运用架构:
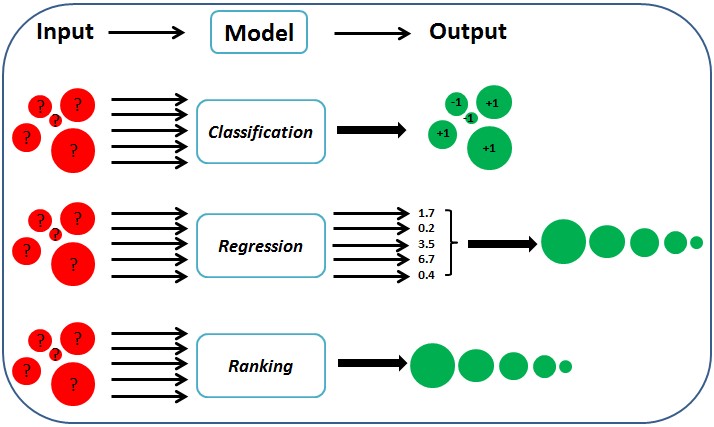
以下是对通用机器学习分类
,L2R分类图解,ref http://www.tongji.edu.cn/~qiliu/lor_vs.html
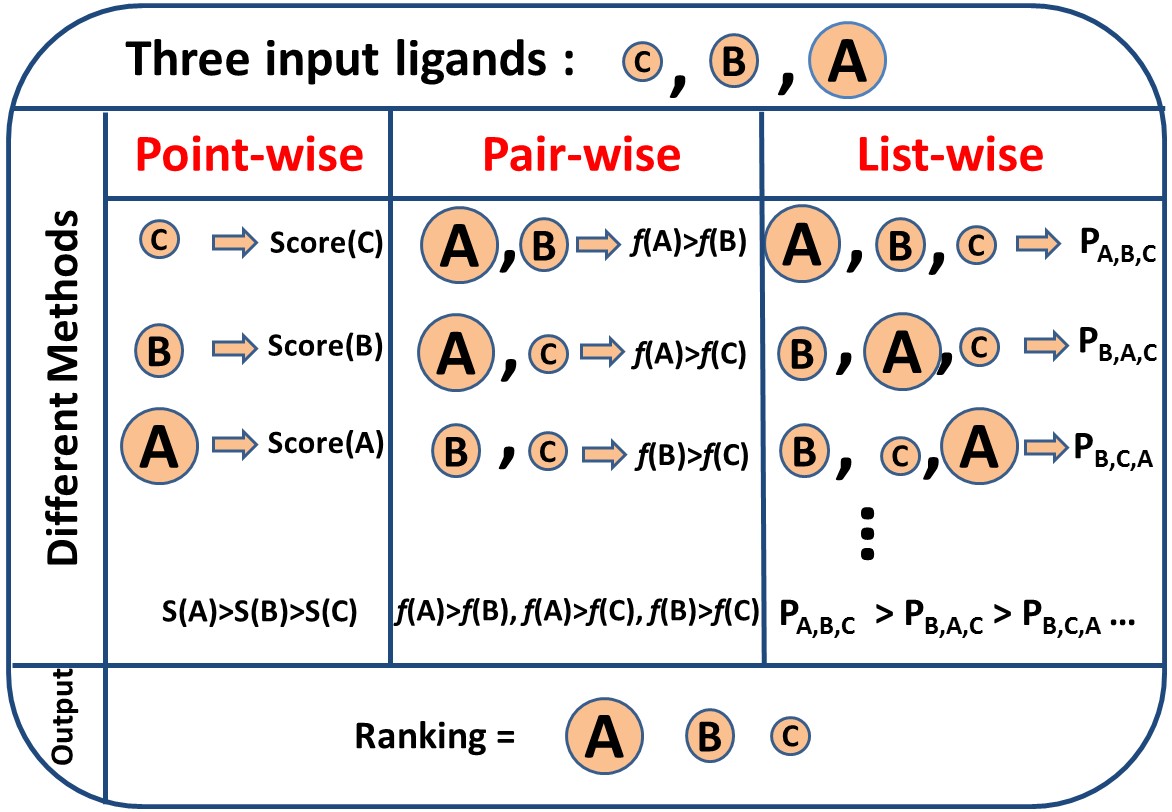
L2R在IR与在RecSys中的区别
L2R在IR与RECSYS中的区别实质上是RECSYS中collaboration based 和 content based的区别,如果RecSys中拥有user,item甚至是用户行为(上下文)特征数据的话,就可直接将L2R in IR中的learning model迁移到RECSYS中。如果RECSYS中只有行为数据而没有特征数据,那么只能利用collaboration方法了,实际上L2R也是可以用在collaboration based的RECSYS中的,原因在于RECSYS中的用户id就可以隐含了所有用户特征(隐特征,这个概念就不能用在query中,因为query没有唯一标识,其id没有任何实质用处,因为系统不能利用query id来索引document, the query is like a new user in RecSys),所以collaboration based方法也不能用在IR中。
LETOR数据的简单介绍
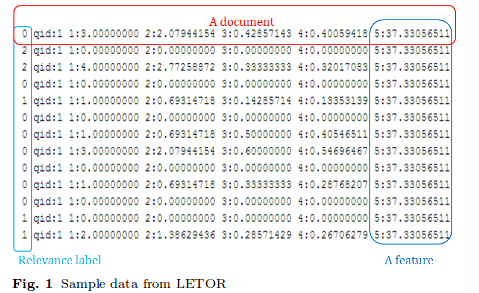
用户输入query,index 相关documents, 确定语料库,计算相关特征,输入到Ranking model, 进行排序。
近期发现二次排序成为很多文章的选择, 如 http://nuoku.vip/users/2/articles/51
| 文献题目 | 去谷歌学术搜索 | ||||||||||
| LETOR: Benchmark Datasets for Learning to Rank | |||||||||||
| 文献作者 | Tie-Yan Liu and Hang Li | ||||||||||
| 文献发表年限 | 2010 | ||||||||||
| 文献关键字 | |||||||||||
| LETOR; L2R: IR | |||||||||||
| 摘要描述 | |||||||||||
| 主要介绍下L2R在IR领域中的应用,尤其区别于L2R在RecSys中的应用. Information Retriveal with Learning to Rank (problem setting) | |||||||||||


