
这篇博文不直接谈文章具体解决问题的方法,但从本文导出的几个问题值得研究和注意:
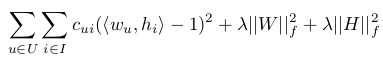
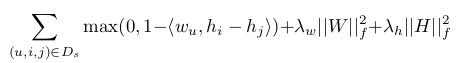
| 文献题目 | 去谷歌学术搜索 | ||||||||||
| BPR: Bayesian Personalized Ranking from Implicit Feedback | |||||||||||
| 文献作者 | Steffen Rendle, Christoph Freudenthaler, Zeno Gantner and Lars Schmidt-Thieme | ||||||||||
| 文献发表年限 | 2009 | ||||||||||
| 文献关键字 | |||||||||||
| BPR; pairwise; 抑制过拟合使得排序成为可能 | |||||||||||
| 摘要描述 | |||||||||||
| Item recommendation is the task of predict- ing a personalized ranking on a set of items (e.g. websites, movies, products). In this paper, we investigate the most common sce- nario with implicit feedback (e.g. clicks, purchases). There are many methods for item recommendation from implicit feedback like matrix factorization (MF) or adaptive k- nearest-neighbor (kNN). Even though these methods are designed for the item predic- tion task of personalized ranking, none of them is directly optimized for ranking. In this paper we present a generic optimization criterion BPR-Opt for personalized ranking that is the maximum posterior estimator de- rived from a Bayesian analysis of the prob- lem. We also provide a generic learning al- gorithm for optimizing models with respect to BPR-Opt. The learning method is based on stochastic gradient descent with bootstrap sampling. We show how to apply our method to two state-of-the-art recommender models: matrix factorization and adaptive kNN. Our experiments indicate that for the task of per- sonalized ranking our optimization method outperforms the standard learning techniques for MF and kNN. The results show the im- portance of optimizing models for the right criterion. | |||||||||||


