
核心思想:套上Bandit policy概念,本质是content-based线性回归模型?
最终优化目标如下:
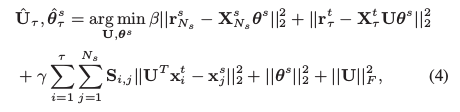
其中,r,X,S (S为两个X之间的联系程度)已知,求U和\theta,U为source domain到target domain的转换矩阵。两次利用U进行的域之间的转换值得借鉴,尤其是直接对content-based的X进行转换。其他方法一般只是对参数\theta 进行转换。问题是:这样用U有道理么?文中说,当source domain 和target domain为同一个领域时,U变为单位矩阵。从这个特例来看,还是有些道理的。
| 文献题目 | 去谷歌学术搜索 | ||||||||||
| Transferable Contextual Bandit for Cross-Domain Recommendation | |||||||||||
| 文献作者 | Bo Liu, Ying Wei, Yu Zhang, Zhixian Yan, Qiang Yang | ||||||||||
| 文献发表年限 | 2018 | ||||||||||
| 文献关键字 | |||||||||||
| bandit policy; 线性 ;linear;exploitation; exploration | |||||||||||
| 摘要描述 | |||||||||||
| Traditional recommendation systems (RecSys) suffer from two problems: the exploitation-exploration dilemma and the cold-start problem. One solution to solving the exploitation- exploration dilemma is the contextual bandit policy, which adaptively exploits and explores user interests. As a result, the contextual bandit policy achieves increased rewards in the long run. The contextual bandit policy, however, may cause the system to explore more than needed in the cold-start situations, which can lead to worse short-term rewards. Cross-domain RecSys methods adopt transfer learning to leverage prior knowledge in a source RecSys domain to jump start the cold-start target RecSys. To solve the two problems together, in this paper, we propose the first applicable transferable contextual bandit (TCB) policy for the cross-domain recommendation. TCB not only benefits the exploitation but also accelerates the exploration in the target RecSys. TCB’s exploration, in turn, helps to learn how to transfer between different domains. TCB is a general algorithm for both homogeneous and heterogeneous domains. We perform both theoretical regret analysis and empirical experiments. The empirical results show that TCB outperforms the state-of-the-art algorithms over time. | |||||||||||


