
本文主要解决L2R中的推荐的长尾问题:
(1)L2R思想:最优化

(2)长尾解决思路:在优化目标中加入正则项,如下:
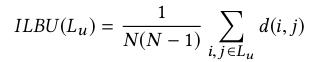
d(i,j)的定义如下:在已经划分好的两个集合:流行物品集合和一般物品集合中,如果i,j分属于两个不同的集合,则d(i,j)=0,否则为1,目标是让推荐的列表中的物品,尽可能一半在流行物品集合中,一半在一般物品集合中。至于最后怎么进行优化的,文中没有给出,只给了参考论文(Incorporating Diversity in a Learning to Rank Recommender System.pdf)。
问题是:参考论文中,距离矩阵D是在P,Q前已知的,而本文中的D是根据PQ的推荐结果计算出来的,难道是每迭代一次求一次D,然后根据参考文献中的求解方法再更新P和Q?
参考文献中:融合diversity的方法是,在原来优化对象的基础上加上一个约束项。此约束项是关于P和Q以及一个物品与物品之间的距离矩阵D(已知)之间的函数。(其中如何把已知的距离和未知的推荐列表推导成关于PQ的函数的方法值得研究)
| 文献题目 | 去谷歌学术搜索 | ||||||||||
| Controlling Popularity Bias in Learning-to-Rank Recommendation | |||||||||||
| 文献作者 | Himan Abdollahpouri; Robin Burke; Bamshad Mobasher | ||||||||||
| 文献发表年限 | 2017 | ||||||||||
| 文献关键字 | |||||||||||
| Recommender systems; long-tail; Recommendation evaluation; Coverage; Learning to rank; 长尾;diversity;多样性 | |||||||||||
| 摘要描述 | |||||||||||
| Many recommendation algorithms suffer from popularity bias in their output: popular items are recommended frequently and less popular ones rarely, if at all. However, less popular, long-tail items are precisely those that are often desirable recommendations. In this paper, we introduce a flexible regularization-based framework to enhance the long-tail coverage of recommendation lists in a learning-to-rank algorithm. We show that regularization provides a tunable mechanism for controlling the trade-off between accuracy and coverage. Moreover, the experimental results using two data sets show that it is possible to improve coverage of long tail items without substantial loss of ranking performance. | |||||||||||


